YOLOV8系列模型部署与后处理
YOLOv8系列模型后处理方案
YOLOv8系列模型是如今工业界使用较多的一些模型, 本文详细描述各类型的输出结构和后处理方案细节。采取的部署方案更偏向边缘端,例如RKNN等,从检测头开始输出,不使用Ultralytics这种常规结构: [1, 4+num_classes, N]的后处理方案。
- 目标检测 (YOLOv8)
- 旋转检测 (YOLOv8-OBB)
- 关键点 (YOLOv8-Pose)
- 实例分割 (YOLOv8-Seg)
模型部署基本流程
模型推理大都经过以下过程
- 预处理Resize、Normalize等, 例如一些Letterbox、归一化(通常为除以255)等,组织图片为需要的输入数据。
- 模型推理,可以是ONNX、RKNN、TensorRT等模型,API有所不同、输入也有可能不同(主要是NCHW与NHWC之间的区别),就是把步骤1获得的图片输入进模型,得到输出。
- 输出后处理,对模型输出进行进一步处理、例如DFL、NMS等内容(一些模型可以通过量化、算子合并与拆分来实现模型的精度与速度平衡,会涉及后处理的变动)。
一、YOLOv8
输入输出
部署的输入输出结构如下:
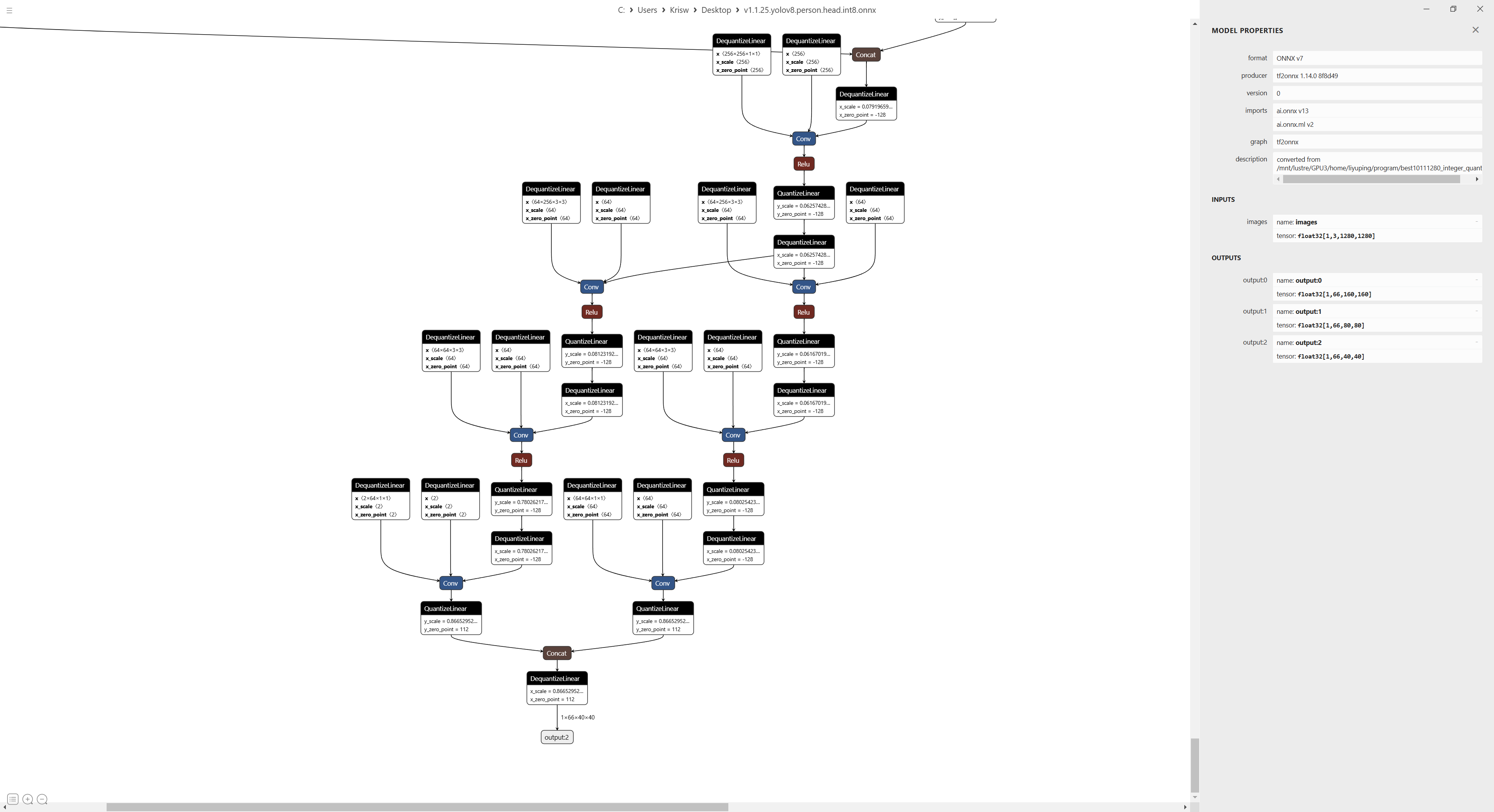
以上模型输入尺寸为[1, 3, 1280, 1280], stride为[8, 16, 32],模型有两个检测类别,三个检测头输出为[1, 66, 160, 160],[1, 66, 80, 80],[1, 66, 40, 40], 每个stride尺寸方格内进行预测,假设stride为8,则1260x1260的尺寸内共有160x160个预测方格。前64组数据用于预测框,后面两个数据表示预测类别置信度,(这个模型中将类别置信度和坐标拼在一起,也可使用RKNN官方部署方案,后处理需要进行一定定的更改), 设定的regmax为16,因此用于计算框的数据长度为16x4为64。
后处理
1. DFL框解码
regmax为16,分为4组,分别预测l、t、b、r分别表示左上的x、y与右下的x、y坐标。首先对16个一组的坐标值进行计算Softmax,与regmax的16个索引值相乘后相加,得到最终的坐标值(这里计算的是一个期望值)。得到输出后,根据中心点计算坐标回归,这里的中心点是每个预测方格的中心点,以stride为8时举例,第一个中心点为(4, 4), 根据这个中心点可以求出这个方格中的预测坐标x1, y1, x2, y2. 代码如下:
1 | C, H, W = output.shape # [66, 160, 160] |
2. 类别预测
类别预测较为简单,对每个预测类别输出做sigmoid即可, 即可得到最终的置信度。(部分网络可能使用Softmax计算,用于输出不可能同时满足两个类别的情况),类别大于conf_thresh阈值需要使用NMS进行进一步过滤。
1 | cls_logits = output[:, NUM_BINS * 4:] |
3. NMS
做NMS是为了过滤一些预测重复的框,选择置信度最高的框。判断标准就是计算IOU,IOU大于阈值的框被认为是重复框,只保留置信度最高的框。
1 | def nms_boxes(boxes, scores, nms_thresh=0.5): |
先计算相交部分面积inter,需要找到相交部分的左上角坐标[xx1, yy1]和右下角坐标[xx2, yy2]。假设原来的两个框坐标分别为[x1, y1, x2, y2],[x1’, y1’, x2’, y2’], xx1与yy1是x1与x1’和y1与y1’比较的较大的坐标,xx2与yy2相反,计算Inter时需要考虑不相交的情况。相并的部分面积就是两个框之和减去inter面积,计算IOU之后即可过滤IOU大于nms_thresh的部分(认为预测的是同一个物体),并且这里会先保留score较大的框。
二、YOLOv8-OBB (旋转检测)
输入输出
部署的输入输出结构如下:
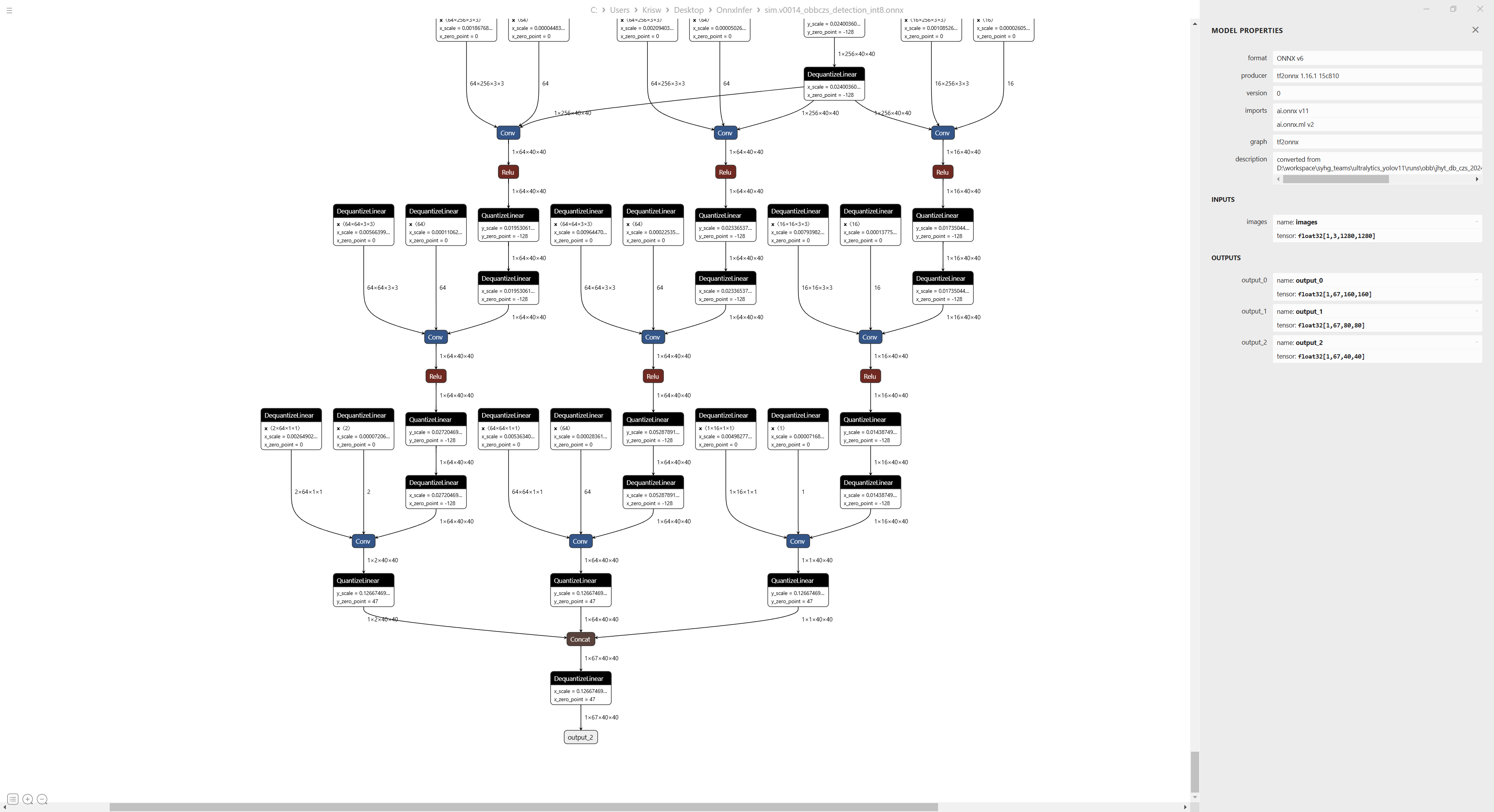
以上模型输入尺寸为[1, 3, 1280, 1280], stride为[8, 16, 32],模型有两个检测类别,三个检测头输出为[1, 67, 160, 160],[1, 67, 80, 80],[1, 67, 40, 40],这个模型中我将角度拼到了预测框后面,最后是分类值。
后处理
1. 角度计算
框计算与类别预测均与YOLOv8一致,角度计算非常简单,根据角度的输出计算真实角度即可,代码如下。这里theta这样计算是为了回归上的稳定,具体原理可参考相关论文
1 | theta = output[num_box_channels, :] # (N,) |
2. RotatedNMS
不同于YOLOv8,obb在计算IOU时需要考虑旋转角度,这里需要使用旋转框的IOU计算方式。
1 | def rotated_iou_numpy(box1, box2): |
计算IOU时相较于普通的矩形框,需要使用旋转框的IOU计算方式,内部实现需要一些空间计算相关知识,不详细展开。Python部署可以使用Shaply、C++可以使用OpenCV。
三、YOLOv8-Pose (关键点检测)
输入输出
部署的输入输出结构如下:
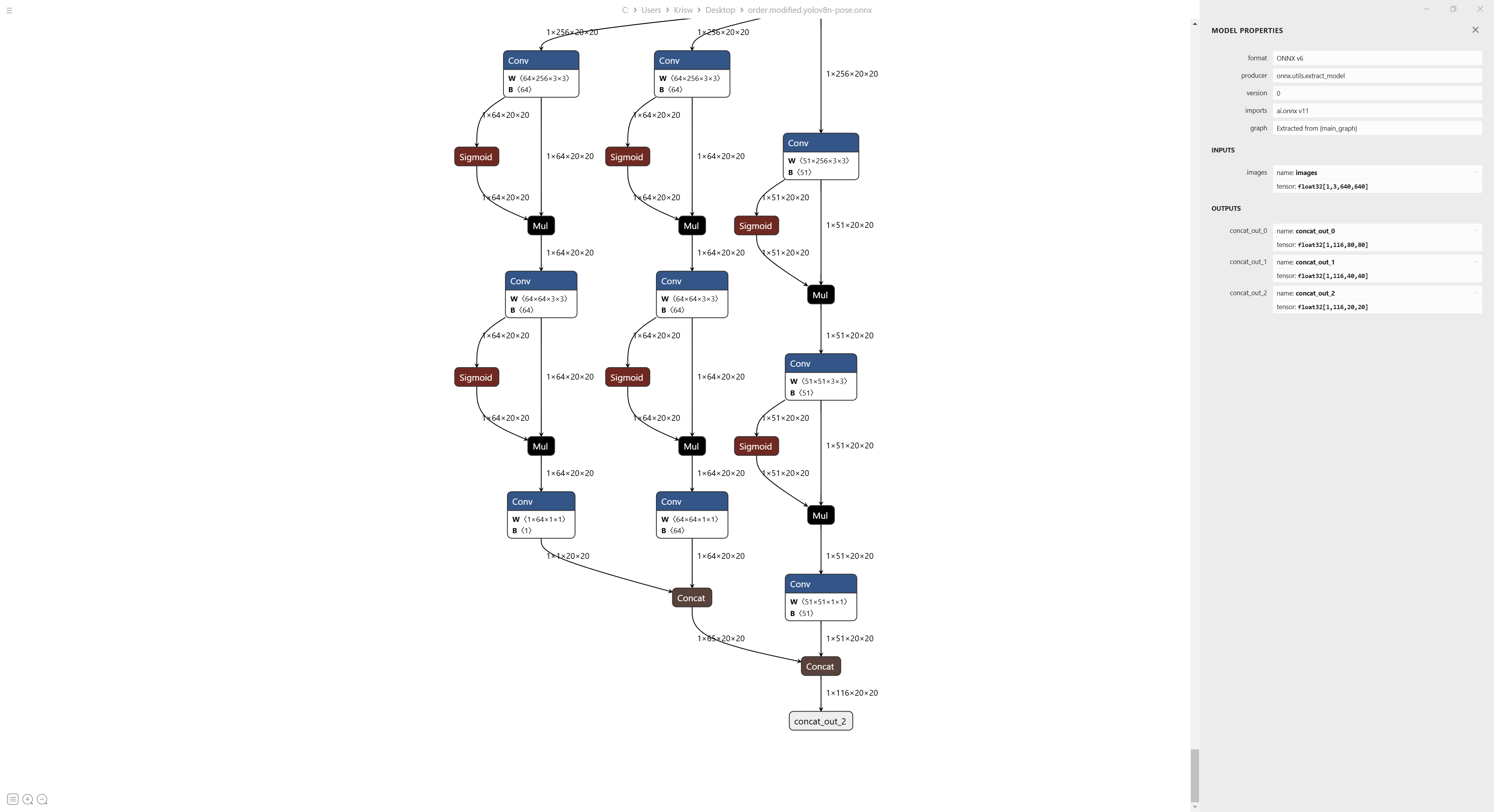
以上模型直接由官方ONNX模型修改而来,输入尺寸为[1, 3, 640, 640], stride为[8, 16, 32],模型只有一个类别,三个检测头输出为[1, 116, 80, 80],[1, 116, 40, 40],[1, 116, 20, 20],这个模型中我将关键点坐标放到了最后面,因此共有64+1+17x3个通道,模型输出17个人体关键点。
后处理
1. 关键点解码
关键点输出是[dx,dy,score …]这样依次排列的,根据坐标回归公式,dx, dy是相较于预测位置(x,y)的偏移量(这里是网格左上角点),实际坐标就是网格左上角点加偏移量[x+2dx, y+2dy],有一些其他的回归方案,要根据具体的版本进行处理。 (现在的版本与我这个模型的版本已经不太一致了,但是都是大同小异,在基准点位置上加上偏移量就能计算出坐标)
1 | y, x = np.divmod(np.arange(H * W), W) |
这个模型只要做好坐标回归计算正确即可。有其他导出方案会输出一个关键点头,并且在模型中完成关键点回归,这种方案不会受到回归方式改变的影响,但是模型精度和速度降低,关键点部分会有一部分无效运算。输出ONNX如下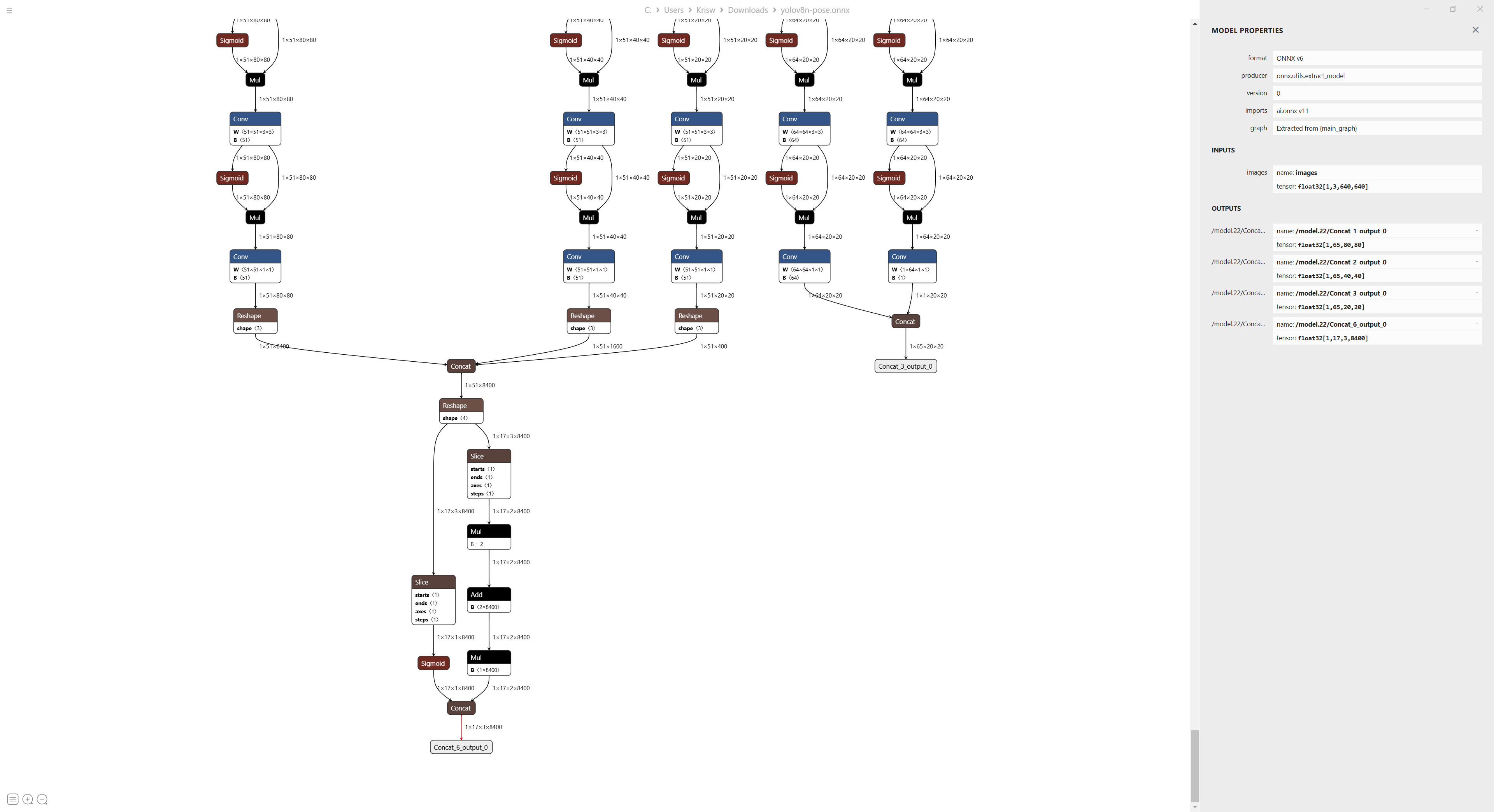
四、YOLOv8-Seg (实例分割)
输入输出
部署的输入输出结构如下:
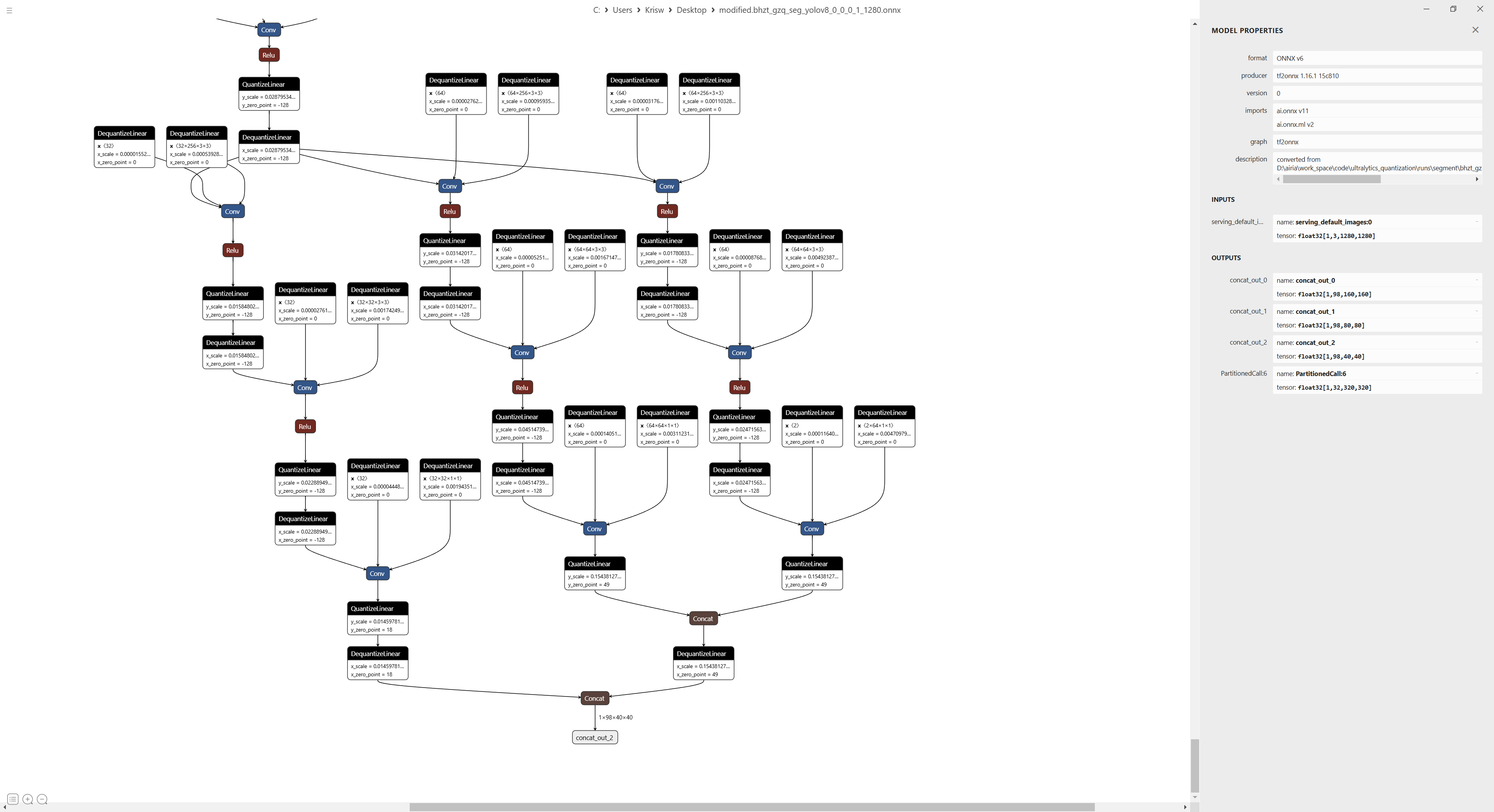
输入尺寸为[1, 3, 1280, 1280], stride为[8, 16, 32],模型两个类别,三个检测头输出为[1, 98, 160, 160],[1, 98, 80, 80],[1, 98, 40, 40],这个模型中我将mask系数放到了最后。并且还有一个[1, 32, 320, 320]的proto_mask用于计算输出。
后处理
1. mask输出计算
YOLO系列都是与框解码联系的,分割的模型处理在于做好mask输出的计算。这里我采用的方法是记录mask系数,做完nms后计算对应的mask。
计算mask时要考虑proto_mask尺寸,需要先resize到输入尺寸,并做一些crop处理(去除框外的mask,去掉letterbox补边的部分), 之后再回归原图的mask。
1 | def process_masks(mask_coeffs, proto_mask, boxes, scale, dw, dh, input_shape=(1280, 1280)): |
mask_coeffs是mask系数,输入维度为[n, 32], proto_mask是[1, 32, 320, 320], boxes是[n, 4],scale是缩放比例,dw,dh是padding的大小,由letterbox计算所得。
总结
YOLO系列都是在预测头的基础上进行的,在网格内预测框位置,解码获得框与类别,关键点和分割知识多预测了关键点与mask系数,处理即可。本文的方案大都是对多个头输出进行拼接的,解码完框后再进一步计算其他信息,以减少一定的运算。